Word, Sentence, Text: Lemmatising the Histoire ancienne
In this guest blog post, Stephen Dörr and Marcus Husar talk about the collaboration between the Dictionnaire étymologique de l‘ancien français (DEAF) and TVOF and what opportunities will be open to researchers as a result.
The Histoire ancienne is one of the oldest prose texts in French. Due to its wide dissemination outside of France, from the British Isles to the Holy Land, and the dynamics of the manuscript tradition the text is important not only for the literary history of France but also for the cultural history of Europe. The online publication of the key manuscripts of the first and second redactions will benefit many disciplines: history, literary studies, linguistics, lexicography.
At the outset of the project the question arose as to how to exploit the lexical material and how to allow open access for further research. One major problem was the large amount of data. With this in mind, the TVOF project team at King’s College London organised a meeting in London with us—Marcus Husar and Stephen Dörr of the Dictionnaire étymologique de l‘ancien français (DEAF)—in December 2016. In collaboration with the TVOF team, we made a plan of action:

DEAF logo.
As a first step, we decided to create a KWIC index (Key Word In Context)—the most common tool for creating a concordance—for each online version of the Histoire ancienne. Wikipedia explains: ‘A KWIC index is formed by sorting and aligning the words within an article title to allow each word (except the stop words) in titles to be searchable alphabetically in the index.’ This index shows in the middle of every line the keyword, which is surrounded by a defined number of words of the context. In addition, for each line the exact information that indicates its position in the text is given.

Figure 1: Example of KWIC index.
Using this index as a starting point, the next step consisted of the lemmatisation of the entire body of words in the texts. Before we describe the way this complex procedure functions, we'd like to explain why such a complete lemmatisation of an Old French text is an important element in understanding the text and which should therefore be the basis for any philological, linguistic or literary analysis.
Medieval texts present a range of problems to modern researchers. One such problem is the non-standardisation of verbal conjugations. Only a lemmatisation of all inflected forms to a standardised infinitive allows us to gather all the different forms. Another challenge is the fact that for each word we find a multitude of different spellings which are the result of temporal (diachronic) or regional (diatopic) traditions and scribal practices. All these forms should be assigned to a keyword, a lemma.
The standard lemma we use corresponds to the form given by the Tobler-Lommatzsch, an excellent dictionary of Old French. It was created on the basis of forms, sometimes hypothetically reconstructed and supposed to date from the middle of the 12th century in the Île-de-France. This regional linguistic variety known as Francien, is now thought to have had limited currency before 1300 but it nonetheless still forms a useful basis for comparison precisely because of Tobler-Lommatzsch’s work.
Another key issue is consistency in the process of creating lemmata. It is important to decide at an early stage of a project which lemma is the reference point for lexical items such as pronouns, as these items present a large variety of forms being the result of spelling and agglutination. For a group project it is also important that each decision is documented and available to all team members. Therefore, the members of the aforementioned meeting decided to develop a lemmatisation tool which shows in a drop-down list all generated lemmas. The user only has to type the first few letters to have access to the desired result.
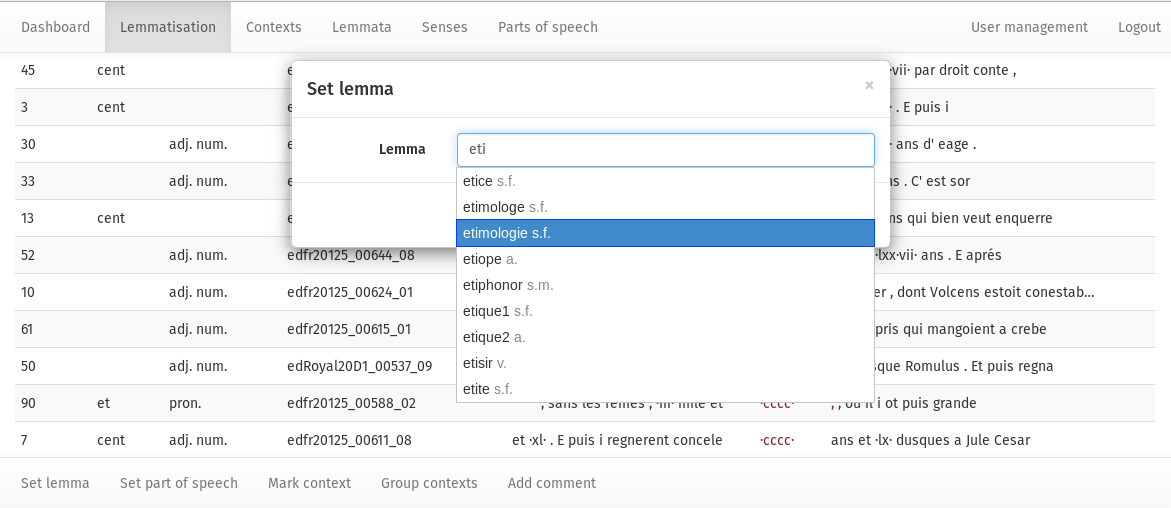
Figure 2: Set lemma dialog in Lemming. Based on an inserted string a drop-down list of predefined lemmata is displayed.
The web application called Lemming was created and developed by Marcus Husar. It is based on the Java Framework Wicket, the Object/Relational Mapping (ORM) framework Hibernate and the Java Platform, Enterprise Edition (Java EE).
Lemming is able to annotate KWIC index entries with attributes like lemma, part of speech, comments and other information. Later on, this could be used as the basic structure for a glossary.
The results will be positive in many ways:
1. The lemmatisation of a text requires the editor to make decisions which engender deep textual comprehension.
2. The creation of a glossary based on a more scientific approach to lexicography ensures textual comprehension which, as just mentioned, is crucial for the process of lemmatisation. This kind of forensic knowledge of the text itself is the foundation of any literary or linguistic interpretation.
3. The assignment of all inflected and agglutinated forms to a defined lemma provides linguists with more reliable data than that of many corpus-based linguistic projects. It also supplies valuable information for other research questions, such as historical research on scriptae.
4. The planned integration of the results of the lexical analysis of the Histoire ancienne into the database of the Dictionnaire étymologique de l’ancien français (DEAF) will link the vocabulary of this key text to the history of French lexis and will also enable the identification of discursive traditions, an opportunity that is not always possible in a 'pure' source analysis. So, the cooperation between a philological project and a dictionary will add to our knowledge of the historical state of a language, which has important implications for the creation of a European identity.
These results will ensure that the Histoire ancienne attains the status in the European history of ideas it deserves.
Stephen Dörr & Marcus Husar